아래의 튜토리얼 내용은 dataiku academy 자료를 참고하여 제작되었습니다.
안녕하세요.
Dataiku의 Lab기능 소개입니다 : )
Dataiku Lab 기능 및 역할
데이터 분석 업무를 하다보면 새로운 아이디어를 실험하고 탐색하는 단계에서 많은 시간을 보냅니다. Dataiku의 Lab은 이를 위한 이상적인 도구입니다.
Lab은 데이터 과학 작업에서 실험과 탐색을 위한 전용 공간으로, 새로운 아이디어를 검증하고 다양한 접근 방식을 시도할 수 있는 환경을 제공합니다. 이를 통해 우리는 프로덕션 워크플로우를 방해하지 않으면서도 새로운 아이디어를 자유롭게 탐구하고 실험할 수 있습니다.
실험과 탐색 공간: 이미 운영 중인 워크플로우를 방해하지 않고 새로운 아이디어를 시도하고 실험할 수 있는 공간입니다. 이를 통해 데이터를 탐구하고 새로운 기술이나 알고리즘, 모델 등을 실험해볼 수 있습니다.
빠른 실험과 반복: Lab에서는 아이디어를 빠르게 시도하고 결과를 확인할 수 있습니다. 즉각적인 피드백을 받으면서 반복적인 실험과 개선을 할 수 있습니다. 이는 모델링이나 데이터 전처리와 같은 작업에서 매우 유용합니다.
협업과 비교: Lab은 팀으로 작업하는 경우 다른 팀원들과 아이디어를 공유하고 비교할 수 있는 환경을 제공합니다. 여러 사람들이 동시에 작업하며 각자의 아이디어와 실험을 수행할 수 있습니다. 이를 통해 팀 내에서 다양한 관점과 접근 방식을 탐색하고, 최적의 솔루션을 찾을 수 있습니다.
워크플로우 관리: Lab은 Flow와 연결되어 있어 프로덕션 워크플로우를 방해하지 않으면서 실험을 할 수 있습니다. 이미 Flow에 구축된 안정적인 작업 흐름을 유지하면서 실험 및 탐색 작업을 분리할 수 있습니다. 이를 통해 Flow가 정리되고 가독성이 향상되며, 필요한 작업만 포함하도록 유지할 수 있습니다.
결과 재사용과 자동화: Lab에서 수행한 작업은 Flow로 배포할 수 있습니다. 이를 통해 Lab에서 개발한 작업을 재사용하고, 자동화하여 더 효율적인 워크플로우를 구축할 수 있습니다.

그냥 FLOW에서 전부 수행해도 괜찮지 않나 라고 생각할 수도 있지만!
위와 같은 이유로 LAB을 유용하게 사용 할 수 있습니다 : )
Lab에서 개발한 작업을 Flow로 배포해보겠습니다!
Basic 103 프로젝트에서 이어서 진행합니다.
customers_orders_joined 데이터셋을 선택 후 LAB 버튼을 누릅니다.
Visual analyses 의 New Analysis 버튼을 클릭하고, Create Analysis 버튼을 눌러 생성합니다!
birthdate 파싱
birthdate 열을 선택하고 드롭다운 목록에서 "Parse date"를 선택합니다.
"yyyy/MM/dd" 형식을 선택하고 "Use Date Format"을 클릭합니다.
Script 단계에서 Output 열을 비워두어 파싱된 날짜가 원래의 birthdate 열을 대체하도록 합니다.
(birthdate를 파싱하면, 새로운 output 열이 생기는데 output 열을 비울 경우 해당 열을 대체하여 결과가 나타남!)
고객의 생년월일과 첫 주문 날짜를 사용하여 첫 주문 시점에 고객의 나이를 계산해보겠습니다.
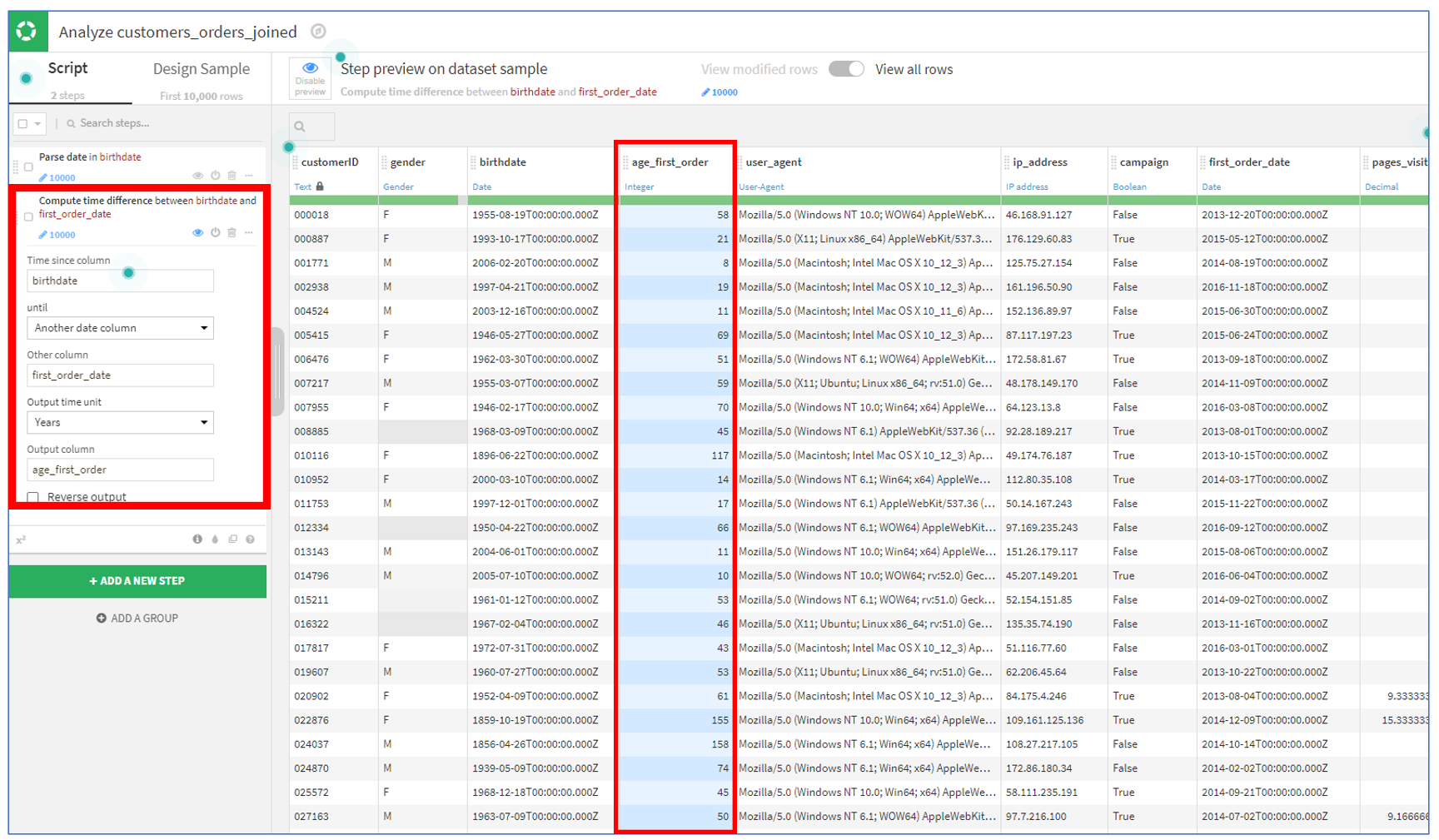
birthdate 열을 클릭하고 드롭다운 목록에서 "Compute time since"를 선택합니다.
"until"을 Another date column으로 선택합니다. (기본은 Now 이므로, 처음에는 현재 나이겠죠!)
"Other column"으로 first_order_date를 선택합니다. (첫 주문 날짜를 기준으로 계산)
"Output time unit"을 Years로 변경합니다.
그런 다음 Output 열 이름을 age_first_order로 편집합니다.
첫 주문 시점의 고객 나이를 알 수 있는 컬럼이 생성되었습니다!
나이를 계산했으므로 분포를 살펴보겠습니다.

age_first_order 열을 클릭하고 드롭다운 목록 에서 "Analyze"를 선택합니다.
120세 이상의 이상값이 여러 개 있습니다. 이상값을 잘못된 데이터를 나타내는 것으로 가정하고 제거해보겠습니다.
Analyze 대화상자에서 Actions 버튼을 클릭합니다. 1.5 IQR (사분위 범위) 바깥의 행을 지우기를 선택합니다.
이제 분포가 더 합리적으로 보이지만, 100을 초과하는 몇 가지 의심스러운 값들이 여전히 있습니다. Analyze 대화상자를 닫아주세요.

Script에서 "Clear values outside [x,y] in age_first_order"를 클릭하고, 상한값을 100으로 설정합니다.
마지막으로, age_first_order를 계산했으므로 birthdate와 first_order_date는 더 이상 필요하지 않습니다. 스크립트에서 이 열들을 제거해주세요! (birthdate와 first_order_date 열 클릭후 ,"Delete"를 선택)
user_agent 열 분석

user_agent 열에는 브라우저와 운영 체제에 관한 정보가 포함되어 있습니다. 이 정보를 별도의 열로 분리하여 추가 분석에 사용할 수 있도록 하고자 합니다.
user_agent 열을 클릭하고, "Classify User-Agent"를 선택합니다. 이렇게 하면 스크립트에 새로운 단계가 추가되고 데이터셋에 일곱 개의 새로운 열이 추가됩니다.

이 튜토리얼에서는 브라우저와 운영 체제에만 관심이 있으므로 필요하지 않은 열을 제거하겠습니다.
빠르게 수행하기 위해 화면 상단 오른쪽 근처에 있는 아이콘을 사용하여 테이블 보기에서 열 보기로 변경합니다.

user_agent_brand , user_agent_os 열은 제외하고 user_agent_로 시작하는 모든 열을 선택합니다.
Actions 버튼을 클릭한 다음 "Delete"를 선택하고, 다시 table 보기로 전환해주세요.

위의 사진이 현재까지의 분석 상황입니다 : )
IP 주소 분석

IP 주소를 활용해보겠습니다. 위의 이미지 처럼 직접 만들어보세요 : )
ip_address 열을 클릭하고, "Resolve GeoIP"를 선택합니다.
이렇게 하면 스크립트에 새로운 단계가 추가되고 데이터셋에는 각 IP 주소의 지리적 위치에 대한 정보를 알려주는 일곱 개의 새로운 열이 추가됩니다.
이 튜토리얼에서는 국가와 GeoPoint(대략적인 경도와 위도)에만 관심이 있습니다.
스크립트 단계에서 "Extract country code", "Extract region", "Extract city"를 선택 해제합니다.
마지막으로, ip_address 열을 삭제해주세요.
Formula 를 활용한 분석

많은 매출을 발생시키는 고객을 식별할 새로운 열을 만들어 보겠습니다. 총 주문 금액이 300을 초과하는 고객을 "고매출" 고객으로 간주합니다.
스크립트에서 +ADD A NEW STEP 을 클릭하고 formula 를 검색하여 선택 합니다.
출력 열 이름으로 high_revenue를 입력하고, OPEN EDITOR PANEL 을 클릭합니다.
표현식으로 if(total_sum > 300, "True", "False")를 입력하고, APPLY 버튼을 눌러주면 새로운 컬럼이 생성됩니다.
Chart 데이터 시각화

고객이 사용하는 브라우저 중 어떤 브라우저가 가장 인기 있는지 도넛 차트를 사용해서 시각화 해보겠습니다.
차트 탭으로 이동하고, 차트 유형 클릭하여 도넛을 선택합니다.
Count of records 를 Show 상자로, user_agent_brand를 By 상자로 드래그합니다.
주문을 한 고객 중 거의 3/4가 Chrome 브라우저를 사용한다는 것을 보여줍니다. 도넛은 각 브라우저의 상대적인 점유율을 전체에 대한 비율로 표시하지만, 우리는 시각화에 OS를 포함시키고 싶습니다.
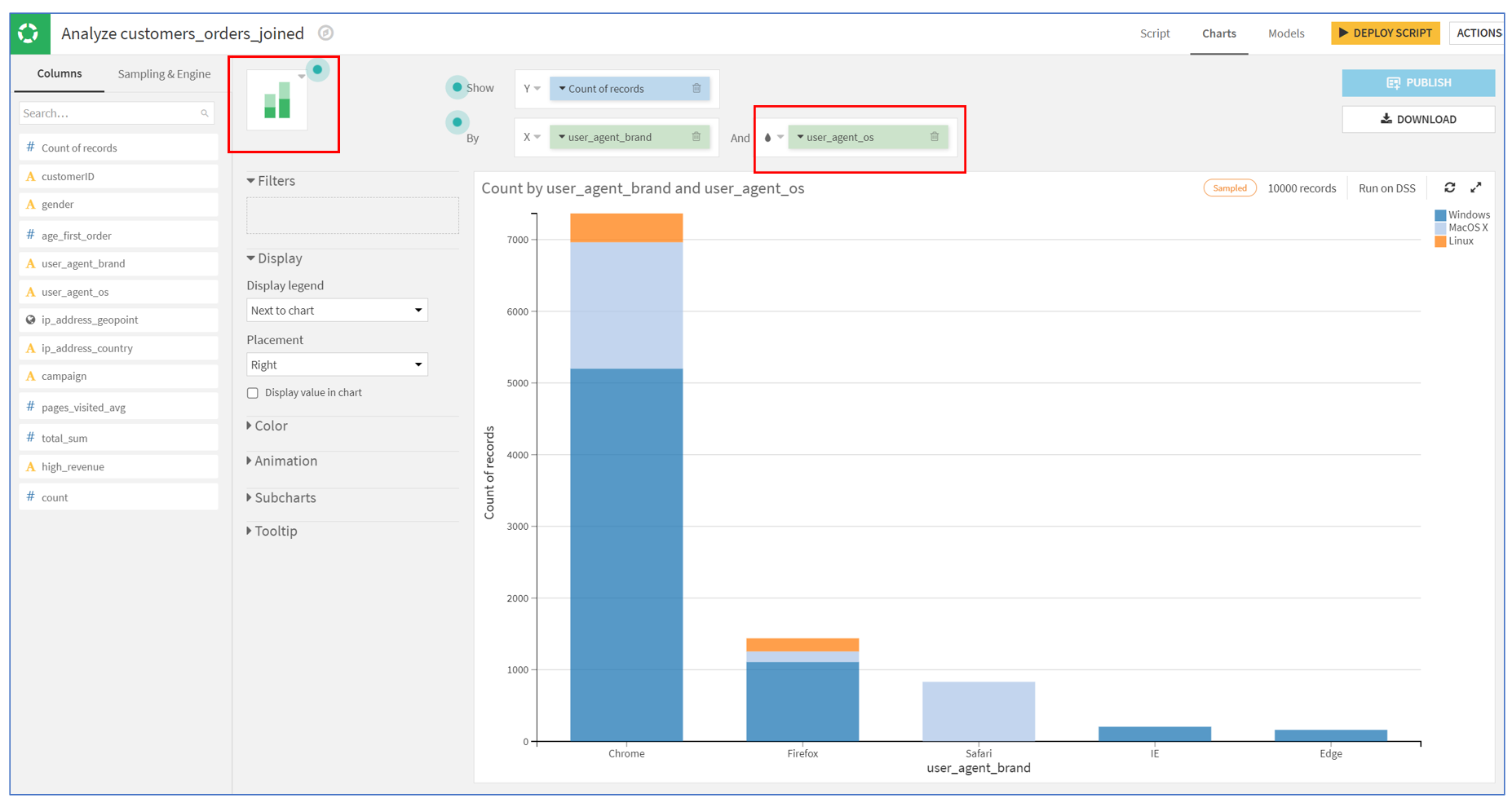
Vertical stacked bars 를 선택하고, user_agent_os를 and 상자로 드래그합니다.
user_agent_os를 추가함으로써 데이터에 대한 추가적인 통찰력을 얻을 수 있습니다. 예상대로, IE와 Edge는 Windows에서만 사용할 수 있으며, Safari는 MacOS에서만 사용할 수 있습니다. 흥미로운 점은 MacOS에서 Chrome을 사용하는 고객 수가 Safari와 Firefox의 합보다 약 두 배 정도 더 많다는 것입니다.
추가로 차트를 더 그려보도록 하겠습니다!

고객의 연령, 캠페인 참여 여부, 그리고 소비액과의 관계를 확인해 보겠습니다.
화면 가운데 하단에 있는 +Chart를 클릭하고, 차트 유형 도구에서 산점도를 선택합니다.
age_first_order를 X축으로, total_sum을 Y축으로 드래그합니다.
campaign을 색상에 드롭, count를 버블의 크기로 설정하는 필드로 드래그합니다.
count 필드 왼쪽에 있는 크기 드롭다운에서, 겹치는 버블을 줄이기 위해 기본 반지름을 5에서 1로 변경합니다.
산점도는 연령이 높은 고객이 그리고 캠페인에 참여한 고객이 가장 많이 소비하는 경향이 있음을 보여줍니다.
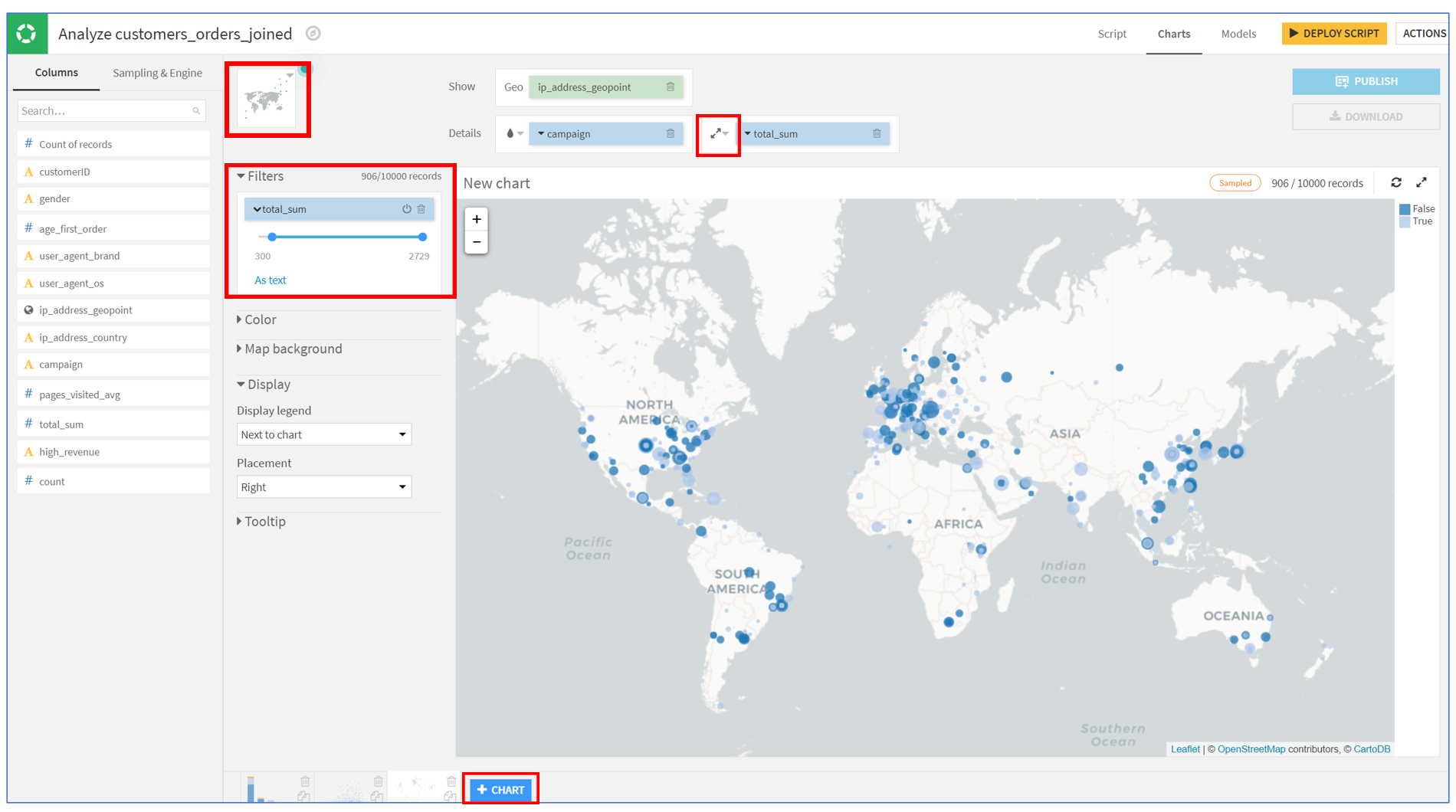
ip_address에서 추출한 위치 정보를 사용하여 고객이 어디에서 왔는지 지도로 시각화해보겠습니다!
세 번째 차트를 생성하기 위해 +Chart를 클릭하고, Scatter map을 선택합니다.
ip_address_geopoint를 Geo 필드로 드래그합니다.
campaign을 색상에 드롭, total_sum을 버블 크기로 설정하는 필드로 드래그합니다.
크기 드롭다운에서, 겹치는 버블을 줄이기 위해 기본 반지름을 5에서 2로 변경합니다.
가장 큰 매출에 초점을 맞추고 싶다면, total_sum을 Filters 상자로 드래그합니다.
하한 값을 편집하기 위해 숫자를 클릭하고, 하한 값으로 300을 입력하여 300보다 작은 소비액을 가진 고객을 필터링 할 수 있습니다.
지금까지 만든 Script를 Flow에 배포해봅시다!

Deploy Script를 클릭하면 스크립트를 Prepare recipe로 배포하기 위한 대화 상자가 나타납니다.
출력 데이터셋의 이름을 customers_labelled로 변경합니다. 레시피를 생성하기 위해 Deploy를 클릭합니다.
레시피를 저장하고 Flow로 이동합니다.
customers_labelled 데이터셋을 열고, 비어 있는 것을 확인합니다. 이는 아직 레시피를 실행하지 않았기 때문입니다!
Build를 클릭하여 데이터셋을 구축합니다.

비재귀적으로 이 데이터셋만 구축할 것인지 아니면 이 데이터셋으로 이어지는 데이터셋을 재구성할 것인지를 묻는 대화 상자가 열립니다. 입력 데이터셋이 최신 상태이므로 비재귀적인 빌드만으로 충분합니다. Build Dataset (non-recursive를 선택한 채로)를 클릭합니다.
작업이 완료되면 출력 데이터셋의 샘플을 확인합니다. 이제 스택 막대 차트를 전체 데이터셋을 사용하도록 구성해 봅시다.
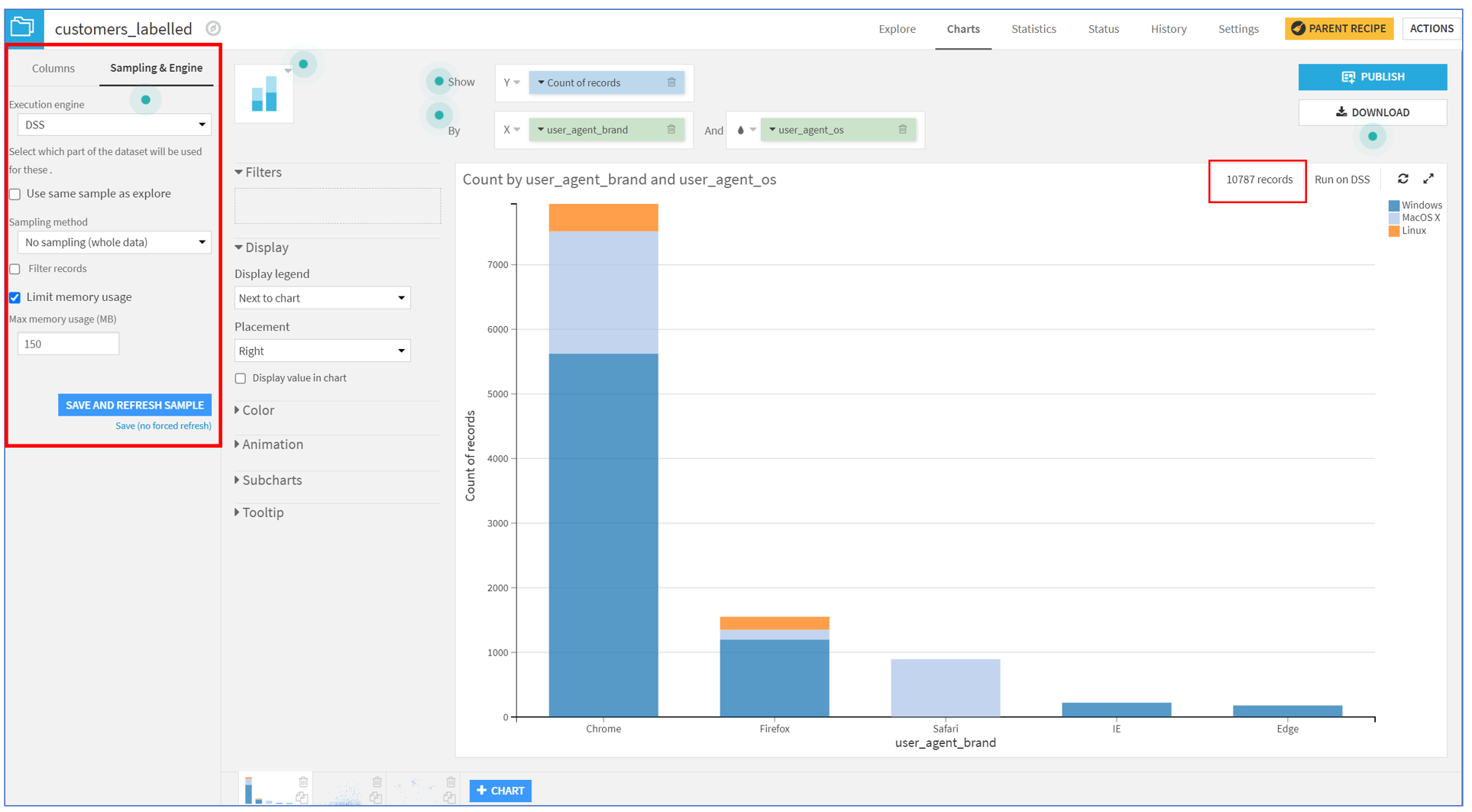
customers_labelled 데이터셋의 Charts 탭으로 이동하고, 왼쪽 패널에서 Sampling & Engine을 클릭합니다.
Use same sample as explore 옵션을 선택 해제 후 샘플링 방법으로 No sampling (whole data)를 선택합니다.
Save and Refresh Sample을 클릭하면 샘플 대신 전체 데이터셋을 사용하도록 구성된 막대 차트가 나옵니다 : )
Lab에서 Flow로 시각 분석 스크립트를 성공적으로 배포했습니다 !
궁금한 내용 있으시면, 댓글로 질문 남겨주세요 : )
'AI 및 데이터 분석' 카테고리의 다른 글
| Dataiku - 레시피 활용 (5) (0) | 2023.06.08 |
|---|---|
| Dataiku - 레시피 활용 (4) (0) | 2023.06.07 |
| Dataiku - 레시피 활용 (3) (1) | 2023.06.04 |
| Dataiku - 레시피 활용 (2) (+ Statistics Worksheet) (0) | 2023.06.03 |
| Dataiku - 레시피 활용 (1) (0) | 2023.06.02 |



